
1. 대용량 기상 관측 데이터(4.3억 건)의 수치형 통계 조회 성능 최적화
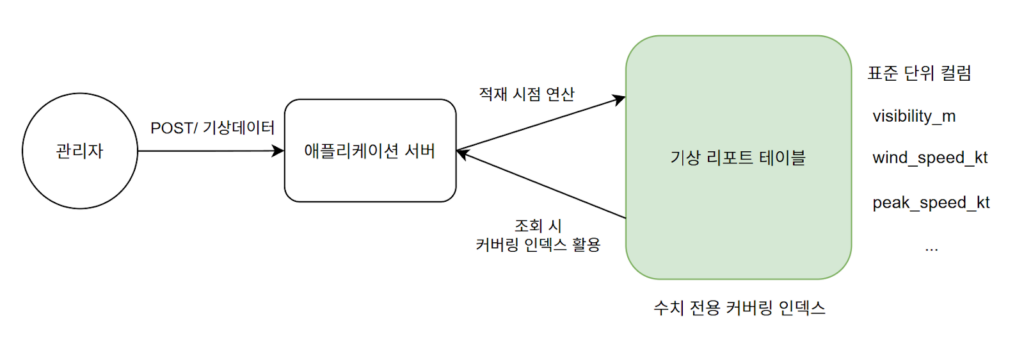
- 전체적인 아키텍처
- 문제 원인
- 기상 테이블에서 공항이름, 관측일시로만 구성된 단일 인덱스 사용(station_icao, report_time_utc)
- 동 상황에서 각 공항의 기간 및 요소별 필터링 시 원본 테이블에 접근하는 랜덤 I/O 발생
- 국가별로 사용하는 기상 단위(KT, MPS, MILE, METER 등)가 상이하여 조회 시점에 단위 변환 함수를 거치거나, 여러 구름 레이어 중 최하층 운고를 계산하는 로직이 쿼리에 포함되어 쿼리 복잡도 증가 및 높은 CPU 부하 유발
- 해결 과정
- 국가별 상이한 단위 체계로 인해 발생하던 연산 비용을 없애기 위해 데이터 적재 시점에 업무 표준 단위로 일괄 변환 후 별도 컬럼에 저장
- 각 구름의 고도 값을 계산하는 로직을 제거하고, 운고 값을 미리 계산하여 데이터 적재 시점에 별도 컬럼에 저장
- 랜덤 I/O 방지를 위해 커버링 인덱스를 구성하되 가변 문자열(기상 코드)을 배제하여 메모리 효율 확보
- 결과
- 원본 테이블 접근 없이 커버링 인덱스 스캔만으로 쿼리를 완료함으로써 조회 속도 대폭 개선
- 업무 표준 단위로 정리된 컬럼만을 사용하도록 일원화하여 쿼리 복잡성 크게 감소
2. 복합 기상 코드 데이터 구조 반정규화 및 검색 전용 캐시 컬럼을 통한 조회 성능 튜닝
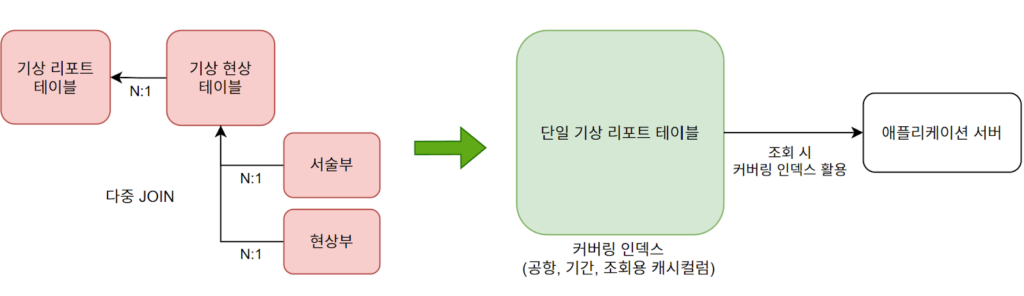
- 전체적인 아키텍처
- 문제 원인
- 기상 현상은 하나의 코드 안에서 강도, 서술부, 현상이 복합적으로 구성됨 (예시: -VCTSSNPL = 공항 인근에서 뇌우를 동반한 약한 강설 및 얼음알갱이 관측됨)
- 데이터 무결성을 위해 복합 코드를 분해하여 여러 개의 별도 테이블로 정규화하여 관리
- ‘강한 뇌우가 포함된 날’과 같은 다차원 통계 조회 시, 테이블 간 다중 조인이 발생하여 응답 속도 저하
- 해결 과정
- 기존의 다중 테이블 구조를 없애고, 분해된 코드를 JSON 컬럼으로 반정규화하여 단일 테이블로 병합. 원본 의미 유실 방지
- 각 기상 코드를 토큰으로 분해 및 조합 후 단일 문자열로 만들어 별도 컬럼(cached_weather_codes)에 저장
- 해당 컬럼을 포함하는 커버링 인덱스를 생성 후, SQL LIKE 연산자를 기반으로 각 토큰이 포함돼있는지 매칭하도록 쿼리 구현
- 결과
- 다중 조인 과정 제거하고 별도 컬럼을 포함하는 커버링 인덱스를 참조함으로써 복잡한 기상 현상 조회 속도 개선
- 단일 테이블 구조로 단순화 함으로써 복잡한 테이블 관리 절차 제거 및 유지보수 비용 최소화
3. 아키텍처 개선을 통한 계층 간 높은 결합도 이슈 해결
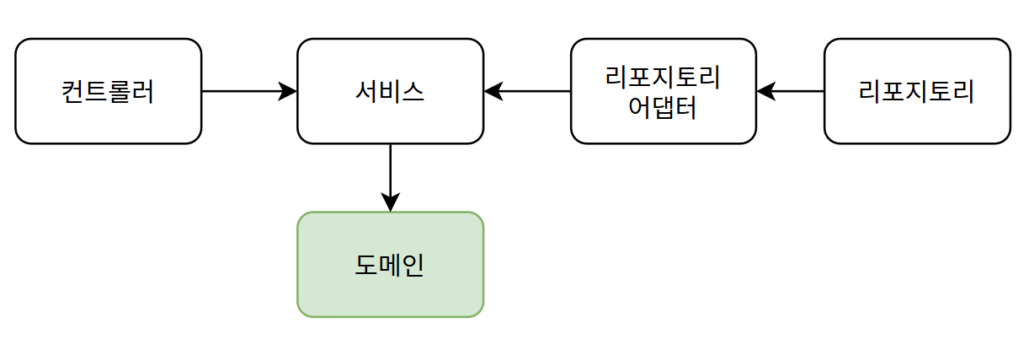
- 전체적인 아키텍처
- 문제 원인
- 전통적인 계층형 아키텍처(컨트롤러-서비스-리포지토리)를 사용해 각 계층이 강하게 종속된 형태로 시스템이 구축됨
- 신규 기능개발 요청 시 기능 구현을 위해 코드의 상당 부분을 고쳐야 하는 문제 발생
- 해결 과정
- 시스템 핵심 비즈니스 로직을 추출하고, 이를 별도 도메인 계층에 격리
- 기존의 서비스 클래스를 실무 기능 단위로 분해하고(UseCase), 이를 애플리케이션 계층에 격리
- 외부 시스템과의 통신은 인터페이스인 포트로 추상화하고, 실제 구현체는 어댑터로 분리하여 구현
- 결과
- 신규 기능 개발 시 UseCase와 관련 구현체만 추가하는 방식으로 개선되어 도메인 보호 및 유지보수성 개선
- 계층별 책임이 분리되어 테스트가 용이한 환경 확보